

Существует множество методик измерения близости политических позиций. Можно анализировать голосования в парламенте: если, к примеру, два депутата часто голосуют одинаковым образом, то их позиции близки, и наоборот.
Можно анализировать тексты: предвыборные программы, стенограммы выступлений и т.п. Наиболее известна методика извлечения политических позиций из текстов, применяемая в международном проекте "Манифесто": эксперты изучают предвыборные документы и заполняют анкету по большому количеству вопросов, отражающих политическую позицию партии. Эти данные агрегируются в один индекс — RILE (Right-LEft),— принимающий значения от -100 до 100. Чем меньше абсолютная величина индекса, тем более центристской является партия.
В Институте прикладной математики им. М.В. Келдыша РАН разработан подход к измерению близости политических позиций, лежащий на стыке математики, политологии и лингвистики.
Рис. 1 Диаграмма сходства для программ "Единой России" и "Яблока" на выборах 2007г.
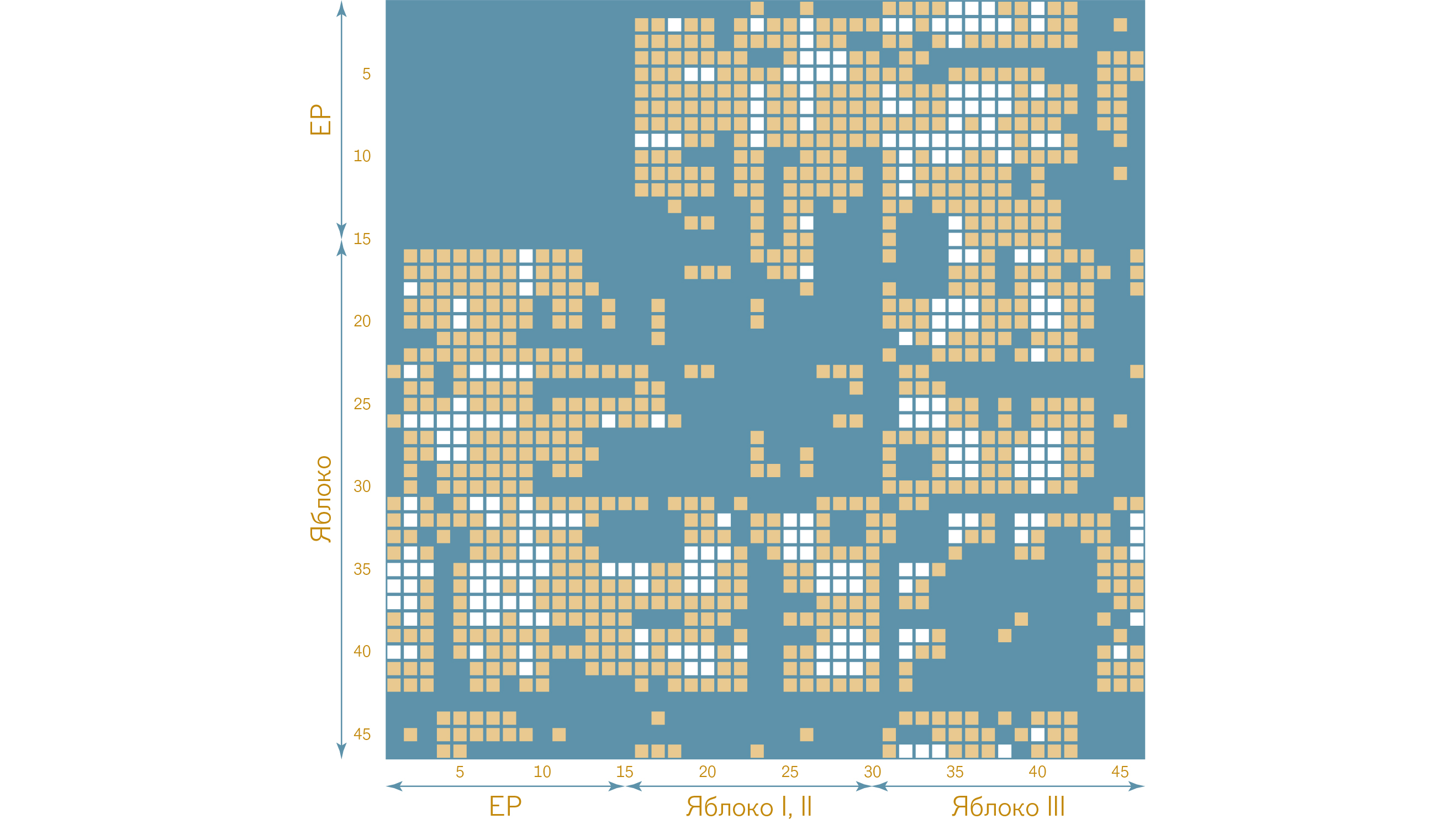
Программа ЕР (фрагменты 1-15) четко отделена от программы "Яблока", в которой можно выделить две внутренне связные части, соответствующие разделам I, II (фрагменты 16-30) и разделу III (фрагменты 31-46).
Парадигматический и синтаксический подходы
Как мы определяем для себя, близки ли два данных слова по значению? Самый простой ответ — сравнив их значения. Например, слова "стул", "диван" и "табуретка" близки в том смысле, что все они обозначают предметы мебели, на которых можно сидеть. Если мы интересуемся близостью слов, значений которых не знаем: скажем, "картуш" и "картулярий", — то можем справиться в словаре. То есть близкие слова — это те, которые имеют близкий "словарный смысл". Такой подход в лингвистике называется парадигматическим.
Применительно к политологии это означает, что если одна из партий пишет о поддержке крестьян, а другая — о поддержке аграриев, то мы делаем вывод: это одно и то же, поскольку "крестьяне" и "аграрии" — это синонимы. Парадигматический подход лежит в основе широкого класса методик анализа текстов, называемого контент-анализом (который, в свою очередь, лежит в основе проекта "Манифесто" и близких к нему методик, использующих экспертное оценивание).
Но есть и другой подход, называемый синтагматическим. Он связан с тем, что значение слова зачастую можно понять по его употреблению, по контексту. Иностранец, изучающий русский язык, прочтя фразу "Вася сидит на стуле, а Петя сидит на табуретке", сможет приблизительно понять (по крайней мере, обоснованно предположить) значение слова "табуретка", если все остальные слова ему известны. То есть в соответствии с синтагматическим подходом значение слова раскрывается через его контекст.
Это позволяет по-новому взглянуть на извлечение политических позиций из текстов. Основная идея новой методики заключается в том, что партии, придерживающиеся различных позиций, погружают одни и те же слова в различный контекст. Например, оппозиционная партия может употреблять слово "правительство" рядом со словами "коррумпированные", "спад", "инфляция", в то время как правящая партия будет употреблять его вместе со словами "реформы", "удалось", "прогресс" и т.д. Таким образом, выражающие политические позиции тексты могут быть классифицированы путем сравнения контекстов.
Рис. 2 Диаграмма сходства для программ "Единой России" и "Яблока" на выборах 2011 года (показаны только строки, соответствующие программе "Яблоко")
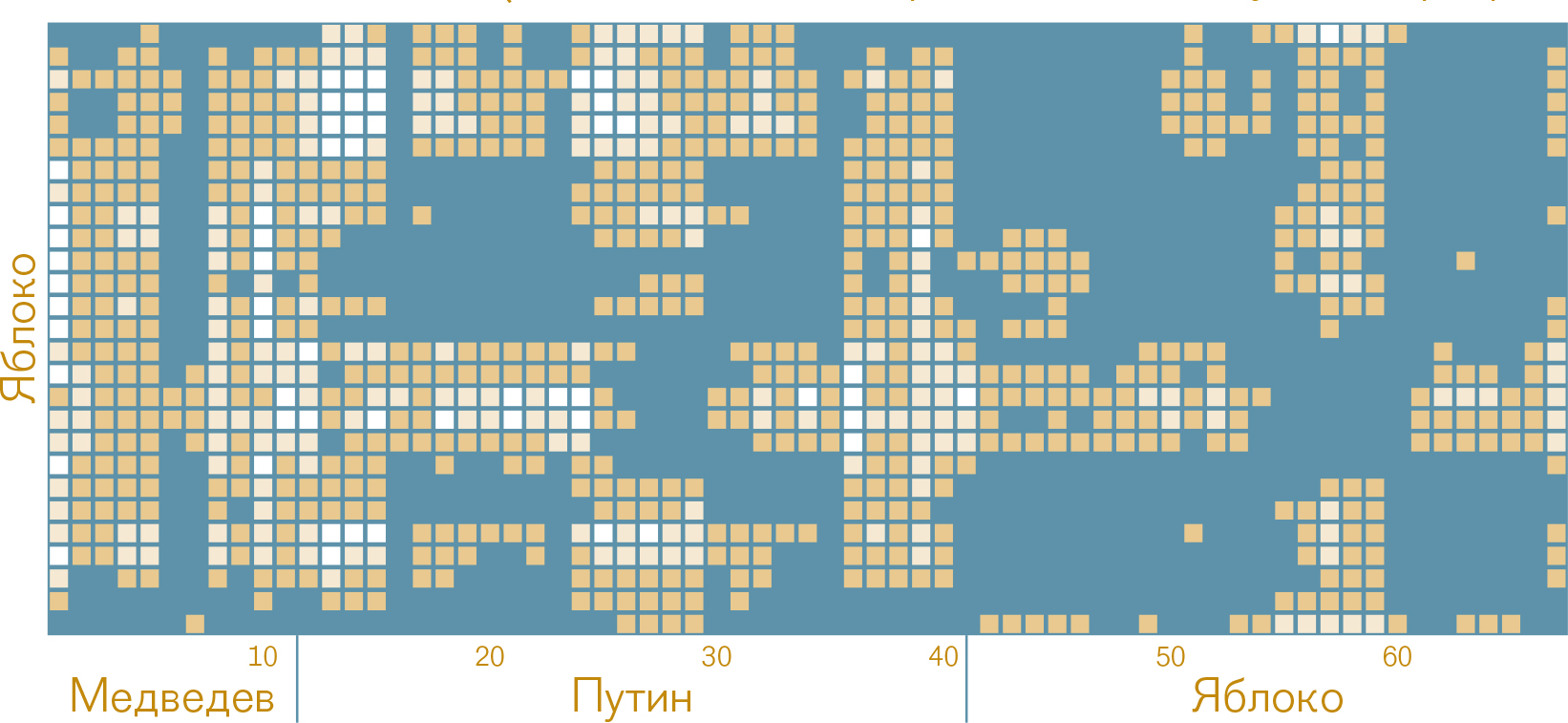
В 2011 г. на съезде "Единой России" было принято решение считать предвыборной программой тексты выступлений Дмитрия Медведева и Владимира Путина. Априори можно было бы предположить, что выступление Медведева, имеющего репутацию либерала, окажется более близким программе "Яблока", чем выступление Путина. Однако ЛСА показывает, что это не так: пересечение столбцов 1-11 (Медведев) и строк 41-67 (программа "Яблока") имеет более светлый тон, чем пересечение столбцов и строк, отражающее сходство выступлений Путина и программы "Яблока".
Автоматический анализ семантической близости
Синтагматический подход реализован группой американских ученых в 1988 г. в виде так называемого латентно-семантического анализа (ЛСА) — метода, позволяющего автоматически анализировать семантическую близость текстов. Основной сферой применения ЛСА являются задачи интеллектуального поиска.
Метод позволяет оценить, насколько фрагменты внутри одного текста близки друг другу. Также с его помощью можно оценить близость фрагмента целому тексту или даже близость отдельных документов друг с другом.

Алгоритм латентно-семантического анализа
ЛСА широко применяется в задачах тематического моделирования. Тематическое моделирование предполагает наличие некой коллекции документов, и для каждого документа необходимо определить тему (или несколько тем), к которой его можно отнести. Типичные примеры задач тематического моделирования: анализ новостных потоков; распределение по рубрикам изображений, видео; определение жанра музыкальных произведений; рубрикация научных статей и т.п.
ЛСА также используется для анализа произведений художественной литературы. В частности, с помощью метода удается с хорошей точностью отличить прозу от поэзии и выявить различные периоды в творчестве авторов.
Важно, что ЛСА — это автоматический метод, не предполагающий экспертной оценки, что выгодно отличает его от традиционных методов выявления близости позиций, выраженных в политических текстах. Он может быть реализован лишь программно, так как исследование даже сравнительно небольшого текста требует проведения довольно сложных и массивных вычислений, которые не могут быть проведены вручную.
Фактически основная идея методики анализа политических текстов, разработанной в Институте прикладной математики, заключается в том, что близость политических позиций связана с синтагматической близостью текстов (фрагментов, образующих тексты), выражающих эти позиции.
Рис. 3 Диаграмма сходства предвыборных программ КПРФ и ЕР 2011 года (показаны только строки, соответствующие программе КПРФ)
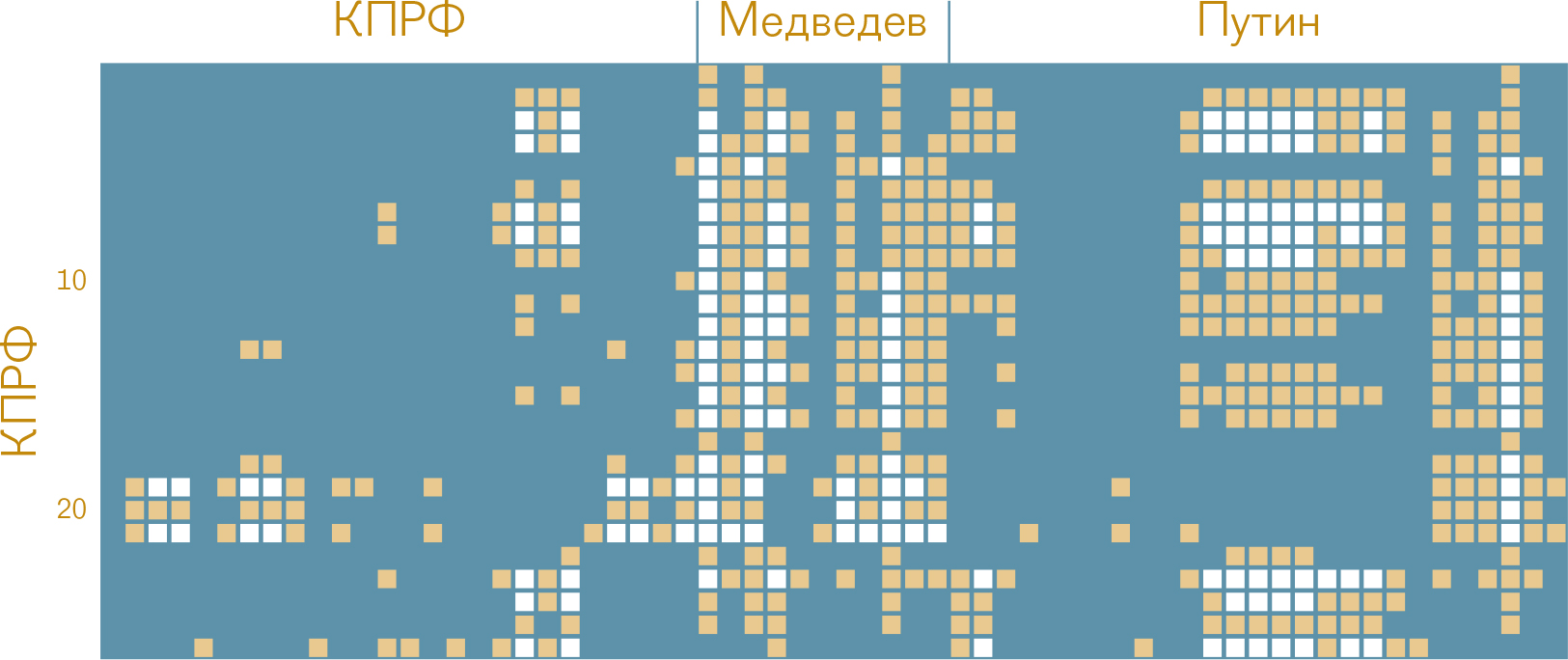
Сопоставление программ КПРФ и ЕР 2011 г. показывает, в частности, что они слабо различимы, если рассматривать программу ЕР как целое. Если же отдельно рассмотреть корреляцию строк 1-26 (КПРФ) со столбцами 27-37 (Медведев) и 38-64 (Путин), то можно отметить несходство программы КПРФ с выступлением Медведева, высокую степень близости с первой частью выступления Путина и расхождение с последней частью.
Разбор применения методики на примере
Запишем одну за другой программы двух партий, например "Единой России" и "Яблока" (в данном случае речь идет о выборах 2007 года). Будем рассматривать это как единый текст и применим к нему алгоритм латентно-семантического анализа. Получим 46 фрагментов, причем первые 15 относятся к программе "Единой России", а фрагменты 16-46 — к программе "Яблока". Результат анализа изображается с помощью диаграммы сходства, представленной на рисунке 01 . Каждому фрагменту соответствуют одна строка и один столбец диаграммы. Ячейка, находящаяся на пересечении, например строки 10 и столбца 25 (как и ячейка на пересечении строки 25 и столбца 10), описывает степень синтагматической близости 10-го и 25-го фрагментов. Чем более синтагматически близкими являются два фрагмента, тем более темным цветом закрашена ячейка. Темный квадрат, составленный из строк и столбцов 1-15, свидетельствует о высокой синтагматической близости этих фрагментов и, в соответствии с нашей гипотезой, — о близости высказанных в этих фрагментах политических позиций. Диаграмма также показывает, что в программе "Яблока" выделяются две части, каждая из которых обладает более высокой внутренней связностью, чем программа в целом. Граница между ними приходится на фрагмент 30. Более подробное рассмотрение показало, что она соответствует границе разделов II "Альтернатива — социальное государство" и III — "Благосостояние для всех" программы "Яблока". Подчеркнем, что граница между разделами II и III программы "Яблока" (как и граница между программами различных партий) определилась автоматически с помощью ЛСА, т.е. без каких-либо "подсказок" относительно структуры единого текста.
Полученные диаграммы визуализируют сходство и различие политических позиций на качественном уровне. Числовая мера близости основана на довольно громоздкой формуле, соответствующей этим диаграммам. Грубо говоря, чем более темным является общий тон соответствующей части диаграммы, тем выше числовое значение близости.